Note
This is the third post in a series on shifting our testing culture.
- Motivation
- Infrastructure
- Code coverage
Most people will say that code coverage is a measure of how well-tested your code is. I prefer to say it's a measure of how untested a codebase is. Take this example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
This yields 66.7% code coverage, but although the test passes, it doesn't validate any business logic because the test has no assertion. The example is a bit derived, but in a more realistic scenario where tools report you have 66.7% code coverage, you don't actually know if that code is actively tested or just happens to be executed while running tests. What you do know is that the other 33.3% is definitely not tested.
llvm-cov
Pedantries aside, code coverage is still important even if the coverage level is already high and there isn't much untested code. That's because code coverage isn't just a number, it also comes with a detailed source overlay: the source code with highlights that indicate which lines, functions, and code branches were invoked while running tests, and how often:
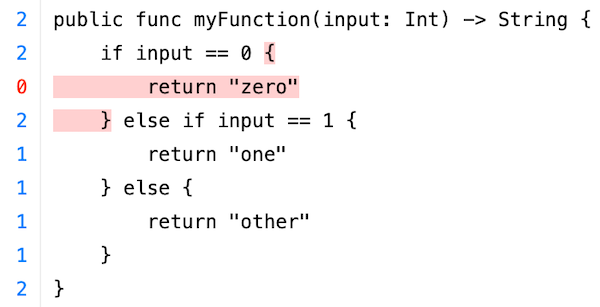
It's clear that although this method has a test, the input == 0 branch wasn't
executed while running them. The return "one" and return "other" lines are
executed once, and the rest of the method is executed twice. Getting full
coverage of this function requires adding a test that calls it with input ==
0.
On iOS, Xcode has built-in support for reporting code coverage. It presumably
uses llvm-cov for user friendliness, but invoking llvm-cov directly gives a
ton of extra options, including exporting in different formats like JSON and
HTML.
Since llvm-cov operates on a test bundle and we have a test bundle for each of
our modules, we can get detailed information about a module's code coverage:
which file and which lines within a file, how many total lines are testable and
how many are covered, etc.
In the past we used the various output formats to integrate with codecov, but
eventually moved to an in-house web portal where this data is stored and easily
accessible. We've also built tooling integration so developers can run a simple
command on their own machine to get llvm-cov's output generated for their
modules, though viewing it in Xcode is often the better choice for local
development. The only part that's missing is seeing the source overlays in
GitHub so you can immediately tell which code changes require more tests.
Tracking coverage
Every time a module's source code or tests change, we capture the new coverage metrics in a database to keep track of a full history of each module's code coverage. We aggregate the data by team and for the codebase as a whole, and display it on the web portal. This gives anyone immediate access to answer common questions about their team's testing progress.
Developers are often interested in more than just the raw code coverage numbers - they also want to understand what code isn't tested so they can add more coverage. To make this easier, the web portal also displays the source overlays for all source files in a module for easy viewing without having to open Xcode for it.
Minimum coverage
When a measure becomes a target, it ceases to be a good measure
- Goodhart's law
Many companies enforce a minimum coverage level all code has to hit. Although it sounds enticing, it could also turn into exactly what Goodhart's law warns about. Developers will likely work around it if they feel they need to, or write low-quality tests just to hit the minimum. It's also not clear what number to pick and what to base that on.
So instead we took a slightly different approach: each module gets to set its
own minimum coverage percentage in the BUILD file, and that percentage is
then enforced by our CI system. It's a good balance between establishing a
minimum while giving developers enough control to not make it feel overbearing.
Developers are free to set that minimum to any percentage they want through a pull request, but lowering it too drastically requires a good justification and comes with social friction. Increases are often celebrated as a job well done.
We also bump the minimum for a given module automatically if it's too low compared to its actual coverage. A module whose minimum coverage is set to 10% but actually has 50% coverage, would get its minimum increased to 45%. This makes it harder to accidentally drop coverage.
Other ideas we've played around with but haven't implemented:
- not allowing decreases in minimum coverage below a certain threshold
- enabling a global minimum but setting it very low (e.g. 20%), in hopes of having to write some tests will lead to writing more
- higher minimum coverage for code that uses highly testable architectural components (as opposed to legacy code that's harder to test)
- tech lead approval for dropping a module's minimum coverage
- requiring adding/updating tests on PRs (changing code without needing to change tests generally means the code is not tested)
Raising the bar
Having a long history of coverage data available has been a big factor in raising the quality bar. During biannual planning, teams get a clear overview of their average coverage and can quickly see which of their modules have the most room for improvement, and attach a measurable goal to it.
We look at overall trends and average coverage levels per module type, and set goals for them for as guidance for other teams. Nothing big, just a couple percent points per quarter, but it makes testing a talking point. When we introduce a new tool, e.g. snapshot tests, we can see how that affects the trend (spoiler alert: our developers strongly prefer snapshot tests) and whether to invest more time/effort.
Developers ask for more or better tests during code review. There has been a noticeable uptick in code changes that just introduce a bunch more tests for existing code. More refactors start out with ensuring code coverage is solid or by closing any testing gaps. If an incident happens, the fix is asked to include a test, and the post-mortem documents the code coverage of the code that was at fault, with an action item to increase coverage if it's too low.
Just like a more testable architecture and better tooling, having insightful code coverage data played a big role in the gradual shift of our iOS testing culture. We started with near 0% coverage, and all the improvements over the years have gotten us to an overall code coverage of 60% and climbing.
To me it's one of the most fascinating leaps in maturity I've seen in my time at Lyft with a ton of learnings along the way.